Elixir streams and list comprehensions



Subscribe to receive Elixir news to your inbox every two weeks.
Expand your skills
Download free e-books, watch expert tech talks, and explore open-source projects. Everything you need to grow as a developer - completely free.
There is a high chance that you have used lists, maps, keywords etc. for some reason or another, and if you used those enumerables, you had to iterate over them, build some data structures, transform them etc.
For most cases, you could write pipeline chains with the help of the Enum module, and call it a day.
But there's more...
More situations require different approaches and, luckily, more ways to go over those enumerables.
To be more specific, we'll take a look at a module called Stream and something called list comprehensions.
Let's start with Elixir streams
By definition, streams are enumerables that generates element one by one(it can be any enumerable), they're technically called lazy enumerables.
As you can guess functions for creating streams are in module Stream. If you take a look in docs for this module you will notice that Stream has most functions that Enum does.
We can say that the functions in Stream are lazy, and the functions in Enum are eager.
Okay, but why should we care?
To see the difference between streams and day to day approach with Enum we are going to explore the following example.
Suppose we have some input from somewhere, and for simplicity's sake, it'll be Range:
some_data = 1..1000Next step, our Enum pipeline will process those data in some way:
operations_with_enum = fn data ->
data
|> Enum.filter(&(rem(&1, 2) == 0))
|> Enum.map(&(&1 * &1))
|> Enum.sum()
endAnd it's counterpart using Stream:
operations_with_stream = fn data ->
data
|> Stream.filter(&(rem(&1, 2) == 0))
|> Stream.map(&(&1 * &1))
|> Enum.sum()
endWe'll test those two functions with benchmark(package name: benchee) to see how they perform:
Benchee.run(
%{
"with_enum" => fn -> operations_with_enum.(some_data) end,
"with_stream" => fn -> operations_with_stream.(some_data) end
},
parallel: 8,
memory_time: 2
)We run the benchmark and the results are:

After looking at the results we see that function using streams to process our data performs a little bit slower but uses much more RAM.
(Hardware specs for reference:
CPU: AMD Ryzen 5 3550H with Radeon Vega Mobile Gfx,
RAM: 16GB
Erlang version: 25.2.3
Elixir: 1.14.0-otp-25
)
Conclusion?
We shouldn't conclude anything yet. As we mentioned before, functions that are in module Enum are eager, and those in module Stream are lazy.
In the case of Stream, values are computed one by one and in the case of Enum they are computed instantly.
Let's see this in action by adding dbg() to the end of the pipeline chain in our functions.
With enum:
some_data = 1..1000
operations_with_enum = fn data ->
data
|> Enum.filter(&(rem(&1, 2) == 0))
|> Enum.map(&(&1 * &1))
|> Enum.sum()
|> dbg()
end
operations_with_enum.(some_data)Output:
data #=> 1..1000
|> Enum.filter(&(rem(&1, 2) == 0)) #=> [2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26, 28, 30, 32, 34, 36, 38, 40, 42,
44, 46, 48, 50, 52, 54, 56, 58, 60, 62, 64, 66, 68, 70, 72, 74, 76, 78, 80, 82,
84, 86, 88, 90, 92, 94, 96, 98, 100, ...]
|> Enum.map(&(&1 * &1)) #=> [4, 16, 36, 64, 100, 144, 196, 256, 324, 400, 484, 576, 676, 784, 900, 1024,
1156, 1296, 1444, 1600, 1764, 1936, 2116, 2304, 2500, 2704, 2916, 3136, 3364,
3600, 3844, 4096, 4356, 4624, 4900, 5184, 5476, 5776, 6084, 6400, 6724, 7056,
7396, 7744, 8100, 8464, 8836, 9216, 9604, 10000, ...]
|> Enum.sum() #=> 167167000As we can see, each time data gets passed to another function from Enum, computed data is returned.
In the case of Stream, it looks differently:
some_data = 1..1000
operations_with_stream = fn data ->
data
|> Stream.filter(&(rem(&1, 2) == 0))
|> Stream.map(&(&1 * &1))
|> Enum.sum()
|> dbg()
end
operations_with_stream.(some_data)Output:
data #=> 1..1000
|> Stream.filter(&(rem(&1, 2) == 0)) #=>
#Stream<[enum: 1..1000, funs: [#Function<40.124013645/1 in Stream.filter/2>]]>
|> Stream.map(&(&1 * &1)) #=>
#Stream<[
enum: 1..1000,
funs: [#Function<40.124013645/1 in Stream.filter/2>,
#Function<48.124013645/1 in Stream.map/2>]
]>
|> Enum.sum() #=> 167167000Functions from Stream don't return data after each pipeline step but rather a keyword list that holds our enumerable under :enum atom and instructions for how to compute a single element from data that we passed under :funs atom. Then at the end of the chain, the function iterates over the values with instructions on how to process them, and it's doing it one by one.
So, an example function that uses Enum to process the data, iterates over them as many times as the length of the pipeline chain.
On the other hand function that utilizes Stream for data processing, iterates over them only once.
Back to our benchmark
Let's see what's gonna happen when we don't have a thousand integers, but millions of them:
some_data = 1..10_000_000And we run the benchmark again:
Benchee.run(
%{
"with_enum" => fn -> operations_with_enum.(some_data) end,
"with_stream" => fn -> operations_with_stream.(some_data) end
},
parallel: 8,
memory_time: 2
)Output:
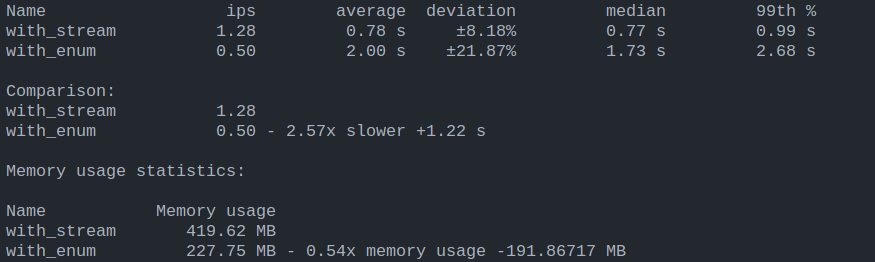
That's a drastic difference, isn't it? Streams were much faster than the classic Enum pipeline. "What about memory? It isn't much of a difference" I hear you say, true, here the difference in memory usage is marginally smaller than last time, but gets wider and wider with more data we have, how much? let's check:
some_data = 1..100_000_000Remember, we added only one zero to the Range and the output is:

Why only with_stream is shown here? I don't exactly know how much with_enum used RAM, but it was for sure more than my hardware can handle(for reference: I have 16GB of RAM).
I hope it shows how much streams are useful when it comes to large and even infinite data.
Now onto list comprehensions
What they are? List comprehension is the sum of two parts(and a few options) that lets us write concise elixir code to ease out repetitive tasks when it comes to iterating over enumerable and building some data structure from them.
They are great alternatives to Stream and Enum, especially to Enum, because most tasks that would result in few iterations, we can reduce it into one iteration with the help of list comprehension.
To write list comprehension we use a special form for.
Let's look at the first part of list comprehensions:
Generators
As you can guess, generators extract values from the enumerables(it can be any enumerable), and we use the <- operator to invoke them. On the right side, we have enumerable, and on the left side, we pattern match a value. Example being:
for n <- [1, 2 ,3] do
n * 2
endAnd the output will be a list:
[2, 4, 6]Simple, yet so handy because we can leverage that pattern match I mentioned earlier, let me show you another example:
data = [ok: 1, error: :error_msg, ok: 2, error: :error_msg]
for {:ok, n} <- data do
n * 2
endOutput:
[2, 4]In a nice and tidy way, we managed to filter out with pattern matching on values from the keyword list that we didn't want and multiplied the rest, at once.
On the other hand, we would have to go over this enumerable twice with Enum, using Enum.filter then Enum.map.
Side note: there's no limit to how many times we can apply the generator in for:
for x <- [1, 2], y <- [3, 4], z <- [5, 6]... do
x * y * z...
endLet me tell you something interesting, you can actually iterate over nested lists with multiple generators!:
data = [["1", "2"], ["3", "4"]]
for first_list <- data, value <- first_list do
value
end
#=> ["1", "2", "3", "4"]Granted, you have to know how deep is nested list.
Filters
You can also apply filters alternatively to pattern matching(or combine them resulting in multiple filters) in generators if you have a more complex case:
for x <- [1, "2", 3, "4", "5"], is_number(x) do
x * x
endbut there is one catch, when the filter must return a truthy value, otherwise value will be discarded.
So, the output for the code above is:
[1, 9]Options for list comprehensions
We can also pass options to list comprehensions, for the time of writing this article there are three: :into, :uniq, :reduce.
:into
As you noticed, every time we invoked list comprehension it returned list, we can change this behavior with the help of :into option.
:into option will take any structure as long as it implements the Collectable protocol. For example:
for x <- [:a, :b, :c], into: %{} do
{x, x |> Atom.to_string()}
end
#=> %{a: "a", b: "b", c: "c"}:uniq
This option is straightforward, when uniq: true is present, then list comprehension returns only those values from enumerable that weren't returned before(ie. returns only unique values).
for {x, y} <- [one: 1, two: 2, three: 3, one: 1], uniq: true do
{x, y * y}
end
#=> [one: 1, two: 4, three: 9]:reduce
Similar to :into, with few differences, first when passing value(enumerable) to :reduce, it becomes an initial accumulator, an accumulator is a value that accumulates output from previous iterations over an enumerable, second difference, now in do end block we must use -> clause where left side receives accumulator and right side must return new accumulator, when there are no more values to iterate over, for returns final accumulator.
:reduce comes in really handy when you need to aggregate values from enumerable. Let me show you an example:
data = [:cd, :vinyl, :cd, :digital_file, :vinyl]
for entry <- data, reduce: %{} do
acc -> Map.update(acc, entry, 1, &(&1 + 1))
end
#=> %{cds: 2, digital_files: 1, vinyl: 2}Conclusion
Whenever we deal with lists, maps, keyword lists, and such, we very often think about utilizing Enum to reach our goals, there is a high chance that it will be a good solution, but there are some cases when we should take time and think about whether we could code our solution better.
With this in mind, we shouldn't forget about other ways we can iterate, transform, and create data structures with the help of Stream and List comprehensions.
Want to power your product with Elixir? We’ve got you covered.
Related posts
Dive deeper into this topic with these related posts
You might also like
Discover more content from this category

Everyone learning a new programming language has probably been there. There’s a missing piece in the new programming language, probably a library.

Time for a final round of the unwritten war between Elixir and Ruby. According to many developers, Elixir is considered Ruby's successor.

While we can't say cheating on anyone is okay, we're not as absolutistic when it comes to cheating on Elixir at times.